From: Norman Geist (norman.geist_at_uni-greifswald.de)
Date: Mon Jun 06 2011 - 06:49:06 CDT
Axel, sure I tested my configuration before telling the world. My results
are very similar to others I found, so let's say my machine is well
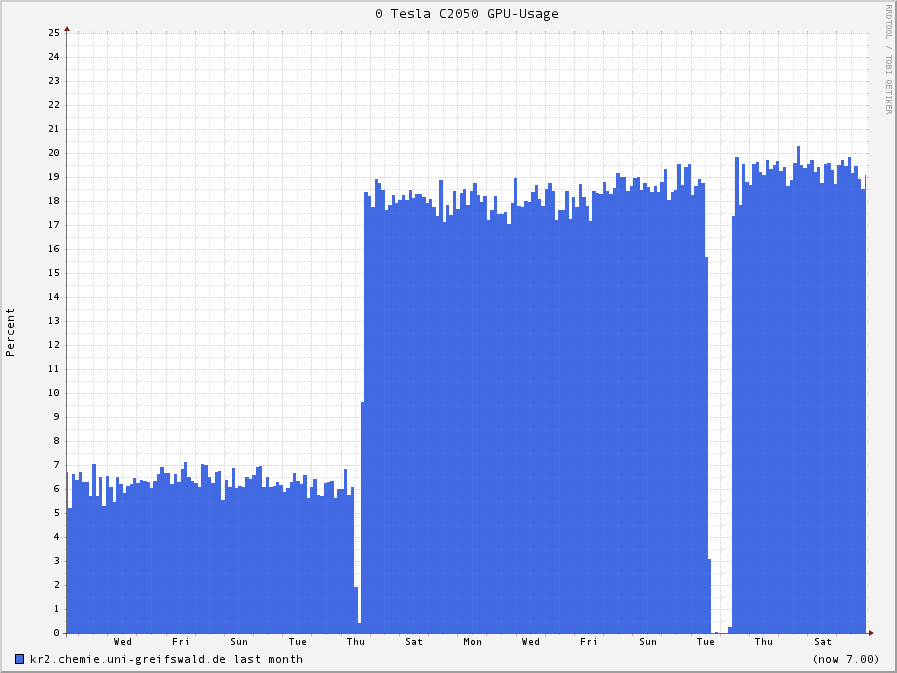
configured. This machine had a dual core processor since I upgraded to a six
core a few days ago. Before that, the utilisation with both cores was about
6%. Don't say this is expectable, because the same gpu runs at 100% with 1
core at acemd. Theres much capacity on the tesla for namd.
The result of the processor change from 2 to 6 was a expectable three times
faster execution and a three time higher utilisation of the gpu (now near
20%). All my tests with increasing numbers of cores (also with the dual
core) that share a gpu are always three times faster than the cpus alone. 6
cores with 1 Tesla C2050 is the same as 6 cores with 2 Tesla C2050 and every
core I add, results in speedup. So I could, if I had, add more cores to see
what happens and when the limit is reached somewhere. But until now, there's
no bottleneck in pcie bandwidth or gpu utilisation with namd.
The graph shows the monitoring before and after the cpu change with namd and
a 1.3 million atoms system.
Norman Geist.
-----Ursprüngliche Nachricht-----
Von: Axel Kohlmeyer [mailto:akohlmey_at_gmail.com]
Gesendet: Montag, 6. Juni 2011 13:30
An: Norman Geist
Cc: Namd Mailing List
Betreff: Re: namd-l: AMD-PhenomII-1075_GTX470 NAMD-CUDA performance
On Mon, Jun 6, 2011 at 7:11 AM, Norman Geist
<norman.geist_at_uni-greifswald.de> wrote:
> Dear Axel,
>
> What I tried to say was that one thing is of course the bandwidth of the
> pcie bus. But what's about the utilization of the gpu? If I have a
> configuration of oversubscription that would still allow communication
> between cpu and gpu due to enough pcie bandwidth, that wouldn't help me if
> my gpu is already fully utilized. And thats what I tried to say. I ran a
> 1,3 million atoms system on a tesla C2050, shared by 6 cpu cores, the
> utilization of the gpu is about 20 percent. I haven't worked with the
i wouldn't be surprised to see such a low utilization since
most of the time is probably spent on moving data in and
out of the GPU. a 6x oversubscription is pretty extreme.
the main benefit is probably in the non-GPU accelerated parts
(which is still a significant amount of work for such a large system).
have you made a systematic test in running different number
of host processes?
please note that high-end GeForce cards can have as many
or even more (GTX 580!) cores than a C2050.
the huge difference in cost between the Tesla and the GeForce
does not automatically translate into different performance for
a code that doesn't benefit from the features of the Tesla
(4x double precision units, more memory, ECC memory,
more reliability). in fact, turning on the ECC of the Tesla may
even slow it down.
axel.
> geforce cards yet, but I can imagine that the utilization of the gpu would
> be much higher here because of the less cuda cores, what means that
further
> cpu cores wouldn't help here, while they would with the tesla C2050. Maybe
> my post was too general and not enough directed to namd, sorry for this.
>
> Norman Geist.
>
>
> -----Ursprüngliche Nachricht-----
> Von: Axel Kohlmeyer [mailto:akohlmey_at_gmail.com]
> Gesendet: Montag, 6. Juni 2011 12:50
> An: Norman Geist
> Cc: Francesco Pietra; Namd Mailing List
> Betreff: Re: namd-l: AMD-PhenomII-1075_GTX470 NAMD-CUDA performance
>
> On Mon, Jun 6, 2011 at 5:51 AM, Norman Geist
> <norman.geist_at_uni-greifswald.de> wrote:
>> Hi Francesco,
>>
>> As your output shows, both gtx cards were in use.
>>
>> Pe 1 sharing CUDA device 1 -> This is gtx 1
>> Pe 0 sharing CUDA device 0 -> This is gtx 2
>>
>> The driver you get from nvidia and from your os is the same I think. The
> nvidia driver must be compiled for your platform, the os driver already
is.
>>
>> If more gpus bring better performance regards heavily on your hardware
and
> system size. Just try if 6 cpus sharing on gtx is slower or the same as
> 6cpus sharing 2 gtx cards. I think the oversubscription of such a gtx is
> limited very quick and u should get better performance while using both
the
> cards.
>
> of course, oversubscribing GPUs can only help up to a point. it doesn't
> create more GPUs, it only allows you to use it more efficiently. think of
> it like hyperthreading. that also it a trick to improve utilization of
> the different
> units on the CPU, but it cannot replace a full processor core and its
> efficiency
> is limited to how much the different units of the CPU are occupied and
> by the available memory bandwidth.
>
>>Not so if using a Tesla C2050. This card can be shared by more than 6
cores
> without running into a bottleneck if plugged into a pcie 2.0 x16 slot.
>
> this is nonsense. as far as the CUDA code in NAMD is concerned there is
not
> much of a difference between a Tesla and a GeForce card. In fact the
> high-end
> GeForce cards are often faster due to having higher memory and processor
> clocks.
> there is, however, the bottleneck of having sufficient PCI-e bus
> bandwidth available,
> but that affects both type of cards.
>
> axel.
>
>> Best regards.
>>
>> Norman Geist.
>>
>> -----Ursprüngliche Nachricht-----
>> Von: owner-namd-l_at_ks.uiuc.edu [mailto:owner-namd-l_at_ks.uiuc.edu] Im
Auftrag
> von Francesco Pietra
>> Gesendet: Montag, 6. Juni 2011 11:16
>> An: NAMD
>> Betreff: Fwd: namd-l: AMD-PhenomII-1075_GTX470 NAMD-CUDA performance
>>
>> I forgot to show the output log:
>>
>> Charm++> scheduler running in netpoll mode.
>> Charm++> Running on 1 unique compute nodes (6-way SMP).
>> Charm++> cpu topology info is gathered in 0.000 seconds.
>> Info: NAMD CVS-2011-06-04 for Linux-x86_64-CUDA
>>
>> Info: Based on Charm++/Converse 60303 for net-linux-x86_64-iccstatic
>> Info: Built Sat Jun 4 02:22:51 CDT 2011 by jim on lisboa.ks.uiuc.edu
>> Info: 1 NAMD CVS-2011-06-04 Linux-x86_64-CUDA 6 gig64 francesco
>> Info: Running on 6 processors, 6 nodes, 1 physical nodes.
>> Info: CPU topology information available.
>> Info: Charm++/Converse parallel runtime startup completed at 0.00653386 s
>> Pe 3 sharing CUDA device 1 first 1 next 5
>> Pe 3 physical rank 3 binding to CUDA device 1 on gig64: 'GeForce GTX
>> 470' Mem: 1279MB Rev: 2.0
>> Pe 1 sharing CUDA device 1 first 1 next 3
>> Pe 1 physical rank 1 binding to CUDA device 1 on gig64: 'GeForce GTX
>> 470' Mem: 1279MB Rev: 2.0
>> Pe 5 sharing CUDA device 1 first 1 next 1
>> Did not find +devices i,j,k,... argument, using all
>> Pe 5 physical rank 5 binding to CUDA device 1 on gig64: 'GeForce GTX
>> 470' Mem: 1279MB Rev: 2.0
>> Pe 0 sharing CUDA device 0 first 0 next 2
>> Pe 0 physical rank 0 binding to CUDA device 0 on gig64: 'GeForce GTX
>> 470' Mem: 1279MB Rev: 2.0
>> Pe 2 sharing CUDA device 0 first 0 next 4
>> Pe 2 physical rank 2 binding to CUDA device 0 on gig64: 'GeForce GTX
>> 470' Mem: 1279MB Rev: 2.0
>> Pe 4 sharing CUDA device 0 first 0 next 0
>> Pe 4 physical rank 4 binding to CUDA device 0 on gig64: 'GeForce GTX
>> 470' Mem: 1279MB Rev: 2.0
>> Info: 1.64104 MB of memory in use based on CmiMemoryUsage
>>
>>
>>
>>
>> ---------- Forwarded message ----------
>> From: Francesco Pietra <chiendarret_at_gmail.com>
>> Date: Mon, Jun 6, 2011 at 9:54 AM
>> Subject: namd-l: AMD-PhenomII-1075_GTX470 NAMD-CUDA performance
>> To: NAMD <namd-l_at_ks.uiuc.edu>
>>
>>
>> Hello:
>>
>> I have assembled a gaming machine with
>>
>> Gigabyte GA890FXA-UD5
>> AMD PhenomII 1075T (3.0 GHz)
>> 2xGTX-470
>> AMD Edition 1280MB GDDRV DX11 DUAL DVI / MINI HDMI SLI ATX
>> 2x 1TB HD software RAID1
>> 16 GB RAM DDR3 1600 MHz
>> Debian amd64 whyzee
>> NAMD_CVS-2011-06-04_Linux-x86_64-CUDA.tar.gz
>> No X server (ssh to machines with X server)
>>
>> In my .bashrc:
>>
>> NAMD_HOME=/usr/local/namd-cuda_4Jun2010nb
>> PATH=$PATH:$NAMD_HOME/bin/namd2; export NAMD_HOME PATH
>> PATH="/usr/local/namd-cuda_4Jun2010nb/bin:$PATH"; export PATH
>>
>> if [ "LD_LIBRARY_PATH" ]; then
>> export
> LD_LIBRARY_PATH="$LD_LIBRARY_PATH:/usr/local/namd-cuda_4Jun2010nb
>> else
>> export LD_LIBRARY_PATH="/usr/local/namd-cuda_4Jun2010nb"
>>
>>
>> I lauched a RAMD rrn on a >200,000-atoms system with
>>
>> charmrun $NAMD_HOME/bin/namd2 ++local +p6 +idepoll ++verbose
>> filename.conf 2>&1 | tee filename.log
>>
>> It runs fine, approximately (by judging from "The last velocity output
>> at each ten-steps writing) ten times faster than a 8-CPU shared-mem
>> machine with dual-opteron 2.2 GHz.
>>
>> I did nothing as to indicating the GTX-470 to use. Can both be used?
>> Is that the same (in terms of performance) using the nvidia-provided
>> cuda driver or the one available with the OS (Debian)?. Sorry for the
>> last two naive questions, perhaps resulting from the stress of the
>> enterprise. I assume that "nvidia-smi" is of no use for these graphic
>> cards.
>>
>> Thanks a lot for advice
>>
>> francesco pietra
>>
>>
>>
>
>
>
> --
> Dr. Axel Kohlmeyer
> akohlmey_at_gmail.com http://goo.gl/1wk0
>
> Institute for Computational Molecular Science
> Temple University, Philadelphia PA, USA.
>
>
-- Dr. Axel Kohlmeyer akohlmey_at_gmail.com http://goo.gl/1wk0 Institute for Computational Molecular Science Temple University, Philadelphia PA, USA.
This archive was generated by hypermail 2.1.6 : Mon Dec 31 2012 - 23:20:23 CST